IBM Will Stop Hiring Professionals For Jobs Artificial Intelligence Might Do
Will AI take jobs and replace people in the future? Large companies are now making room for artificial intelligence alternatives by reducing hiring for positions that AI is expected to be able to fill. Bloomberg reported earlier in May that International Business Machines (IBM) expects to pause the hiring for thousands of positions that could be replaced by artificial intelligence in the coming years.
IBM’s CEO Arvind Krishna said in an interview with Bloomberg that hiring will be slowed or suspended for non-customer-facing roles, such as human resources, which makes up make up 26,000 positions at the tech giant. Watercooler talk of how AI may alter the workforce has been part of discussions in offices across the globe in recent months. IBM’s policy helps define in real terms the impact AI will have. Krishna said he expects about 30% of nearly 26,000 positions could be replaced by AI over a five-year period at the company, that’s 7,800 supplanted by AI.
IBM employs 260,000 people, the positions that involve interacting with customers and developing software are not on the chopping block Krishna said in the interview.
Image credit: Focal Foto (Flickr)
Global Job Losses
In a recent Goldman Sachs research report titled, Generative AI could raise global GDP by 7%, it was shown that 66% of all occupations could be partially automated by AI. This could, over time, allow for more productivity. The report’s specifics are written on the contingency that “generative AI delivers on its promised capabilities.” If it does, Goldman believes 300 million jobs could be threatened in the U.S. and Europe. If AI evolves as promised, Goldman estimates that one-fourth of current work could be accomplished using generative AI.
Sci-fi images of a future where robots replace human workers have existed since the word robot came to life in 1920. The current quick acceleration of AI programs, including ChatGPT and other OpenAI.com products, has ignited concerns that society is not yet ready to reckon with a massive shift in how production can be met without payroll.
Should Workers Worry?
Serial entrepreneur Elon Musk is one of the most vocal critics of AI. He is one of the founders of OpenAI, and the robot division at Tesla. In April, Musk claimed in an interview with Tucker Carlson on Fox News that he believes tech executives like Google’s Larry Page are “not taking AI safety seriously enough.” Musk asserts that he’s been called a “speciesist” for raising alarm bells about AI’s impact on humans, his concern is so great that he is moving forward with his own AI company—X.AI. This, he says, is in response to the recklessness of tech firms.
IBM now has digital labor solutions which help customers automate labor-intensive tasks such as data entry. “In digital labor, we are helping finance, accounting, and HR teams save thousands of hours by automating what used to belabor intensive data-entry tasks,” Krishna said on the company’s earnings call on April 19. “These productivity initiatives free up spending for reinvestment and contribute to margin expansion.”
Technology and innovation have always benefitted households in the long term. The industrial revolution, and later the technology revolution, at first did eliminate jobs. Later the human resources made available by machines increased productivity by freeing up people to do more. Productivity, or increased GDP, is equivalent to a wealthier society as GDP per capita increases.
AI-Generated Spam May Soon Be Flooding Your Inbox – It Will Be Personalized to Be Especially Persuasive
Each day, messages from Nigerian princes, peddlers of wonder drugs and promoters of can’t-miss investments choke email inboxes. Improvements to spam filters only seem to inspire new techniques to break through the protections.
Now, the arms race between spam blockers and spam senders is about to escalate with the emergence of a new weapon: generative artificial intelligence. With recent advances in AI made famous by ChatGPT, spammers could have new tools to evade filters, grab people’s attention and convince them to click, buy or give up personal information.
This article was republished with permission from The Conversation, a news site dedicated to sharing ideas from academic experts. It represents the research-based findings and thoughts of John Licato, Assistant Professor of Computer Science and Director of AMHR Lab, University of South Florida.
As director of the Advancing Human and Machine Reasoning lab at the University of South Florida, I research the intersection of artificial intelligence, natural language processing and human reasoning. I have studied how AI can learn the individual preferences, beliefs and personality quirks of people.
This can be used to better understand how to interact with people, help them learn or provide them with helpful suggestions. But this also means you should brace for smarter spam that knows your weak spots – and can use them against you.
Spam, Spam, Spam
So, what is spam?
Spam is defined as unsolicited commercial emails sent by an unknown entity. The term is sometimes extended to text messages, direct messages on social media and fake reviews on products. Spammers want to nudge you toward action: buying something, clicking on phishing links, installing malware or changing views.
Spam is profitable. One email blast can make US$1,000 in only a few hours, costing spammers only a few dollars – excluding initial setup. An online pharmaceutical spam campaign might generate around $7,000 per day.
Legitimate advertisers also want to nudge you to action – buying their products, taking their surveys, signing up for newsletters – but whereas a marketer email may link to an established company website and contain an unsubscribe option in accordance with federal regulations, a spam email may not.
Spammers also lack access to mailing lists that users signed up for. Instead, spammers utilize counter-intuitive strategies such as the “Nigerian prince” scam, in which a Nigerian prince claims to need your help to unlock an absurd amount of money, promising to reward you nicely. Savvy digital natives immediately dismiss such pleas, but the absurdity of the request may actually select for naïveté or advanced age, filtering for those most likely to fall for the scams.
Advances in AI, however, mean spammers might not have to rely on such hit-or-miss approaches. AI could allow them to target individuals and make their messages more persuasive based on easily accessible information, such as social media posts.
Future of Spam
Chances are you’ve heard about the advances in generative large language models like ChatGPT. The task these generative LLMs perform is deceptively simple: given a text sequence, predict which token – think of this as a part of a word – comes next. Then, predict which token comes after that. And so on, over and over.
Somehow, training on that task alone, when done with enough text on a large enough LLM, seems to be enough to imbue these models with the ability to perform surprisingly well on a lot of other tasks.
Multiple ways to use the technology have already emerged, showcasing the technology’s ability to quickly adapt to, and learn about, individuals. For example, LLMs can write full emails in your writing style, given only a few examples of how you write. And there’s the classic example – now over a decade old – of Target figuring out a customer was pregnant before her father knew.
Spammers and marketers alike would benefit from being able to predict more about individuals with less data. Given your LinkedIn page, a few posts and a profile image or two, LLM-armed spammers might make reasonably accurate guesses about your political leanings, marital status or life priorities.
Our research showed that LLMs could be used to predict which word an individual will say next with a degree of accuracy far surpassing other AI approaches, in a word-generation task called the semantic fluency task. We also showed that LLMs can take certain types of questions from tests of reasoning abilities and predict how people will respond to that question. This suggests that LLMs already have some knowledge of what typical human reasoning ability looks like.
If spammers make it past initial filters and get you to read an email, click a link or even engage in conversation, their ability to apply customized persuasion increases dramatically. Here again, LLMs can change the game. Early results suggest that LLMs can be used to argue persuasively on topics ranging from politics to public health policy.
Good for the Gander
AI, however, doesn’t favor one side or the other. Spam filters also should benefit from advances in AI, allowing them to erect new barriers to unwanted emails.
Spammers often try to trick filters with special characters, misspelled words or hidden text, relying on the human propensity to forgive small text anomalies – for example, “c1îck h.ere n0w.” But as AI gets better at understanding spam messages, filters could get better at identifying and blocking unwanted spam – and maybe even letting through wanted spam, such as marketing email you’ve explicitly signed up for. Imagine a filter that predicts whether you’d want to read an email before you even read it.
Despite growing concerns about AI – as evidenced by Tesla, SpaceX and Twitter CEO Elon Musk, Apple founder Steve Wozniak and other tech leaders calling for a pause in AI development – a lot of good could come from advances in the technology. AI can help us understand how weaknesses in human reasoning might be exploited by bad actors and come up with ways to counter malevolent activities.
All new technologies can result in both wonder and danger. The difference lies in who creates and controls the tools, and how they are used.
AI Has Social Consequences, But Who Pays the Price?
As public concern about the ethical and social implications of artificial intelligence keeps growing, it might seem like it’s time to slow down. But inside tech companies themselves, the sentiment is quite the opposite. As Big Tech’s AI race heats up, it would be an “absolutely fatal error in this moment to worry about things that can be fixed later,” a Microsoft executive wrote in an internal email about generative AI, as The New York Times reported.
In other words, it’s time to “move fast and break things,” to quote Mark Zuckerberg’s old motto. Of course, when you break things, you might have to fix them later – at a cost.
In software development, the term “technical debt” refers to the implied cost of making future fixes as a consequence of choosing faster, less careful solutions now. Rushing to market can mean releasing software that isn’t ready, knowing that once it does hit the market, you’ll find out what the bugs are and can hopefully fix them then.
However, negative news stories about generative AI tend not to be about these kinds of bugs. Instead, much of the concern is about AI systems amplifying harmful biases and stereotypes and students using AI deceptively. We hear about privacy concerns, people being fooled by misinformation, labor exploitation and fears about how quickly human jobs may be replaced, to name a few. These problems are not software glitches. Realizing that a technology reinforces oppression or bias is very different from learning that a button on a website doesn’t work.
This article was republished with permission from The Conversation, a news site dedicated to sharing ideas from academic experts. It represents the research-based findings and thoughts of Casey Fiesler,Associate Professor of Information Science, University of Colorado Boulder.
As a technology ethics educator and researcher, I have thought a lot about these kinds of “bugs.” What’s accruing here is not just technical debt, but ethical debt. Just as technical debt can result from limited testing during the development process, ethical debt results from not considering possible negative consequences or societal harms. And with ethical debt in particular, the people who incur it are rarely the people who pay for it in the end.
Off to the Races
As soon as OpenAI’s ChatGPT was released in November 2022, the starter pistol for today’s AI race, I imagined the debt ledger starting to fill.
Within months, Google and Microsoft released their own generative AI programs, which seemed rushed to market in an effort to keep up. Google’s stock prices fell when its chatbot Bard confidently supplied a wrong answer during the company’s own demo. One might expect Microsoft to be particularly cautious when it comes to chatbots, considering Tay, its Twitter-based bot that was almost immediately shut down in 2016 after spouting misogynist and white supremacist talking points. Yet early conversations with the AI-powered Bing left some users unsettled, and it has repeated known misinformation.
When the social debt of these rushed releases comes due, I expect that we will hear mention of unintended or unanticipated consequences. After all, even with ethical guidelines in place, it’s not as if OpenAI, Microsoft or Google can see the future. How can someone know what societal problems might emerge before the technology is even fully developed?
The root of this dilemma is uncertainty, which is a common side effect of many technological revolutions, but magnified in the case of artificial intelligence. After all, part of the point of AI is that its actions are not known in advance. AI may not be designed to produce negative consequences, but it is designed to produce the unforeseen.
However, it is disingenuous to suggest that technologists cannot accurately speculate about what many of these consequences might be. By now, there have been countless examples of how AI can reproduce bias and exacerbate social inequities, but these problems are rarely publicly identified by tech companies themselves. It was external researchers who found racial bias in widely used commercial facial analysis systems, for example, and in a medical risk prediction algorithm that was being applied to around 200 million Americans. Academics and advocacy or research organizations like the Algorithmic Justice League and the Distributed AI Research Institute are doing much of this work: identifying harms after the fact. And this pattern doesn’t seem likely to change if companies keep firing ethicists.
Speculating – Responsibly
I sometimes describe myself as a technology optimist who thinks and prepares like a pessimist. The only way to decrease ethical debt is to take the time to think ahead about things that might go wrong – but this is not something that technologists are necessarily taught to do.
Scientist and iconic science fiction writer Isaac Asimov once said that sci-fi authors “foresee the inevitable, and although problems and catastrophes may be inevitable, solutions are not.” Of course, science fiction writers do not tend to be tasked with developing these solutions – but right now, the technologists developing AI are.
So how can AI designers learn to think more like science fiction writers? One of my current research projects focuses on developing ways to support this process of ethical speculation. I don’t mean designing with far-off robot wars in mind; I mean the ability to consider future consequences at all, including in the very near future.
This is a topic I’ve been exploring in my teaching for some time, encouraging students to think through the ethical implications of sci-fi technology in order to prepare them to do the same with technology they might create. One exercise I developed is called the Black Mirror Writers Room, where students speculate about possible negative consequences of technology like social media algorithms and self-driving cars. Often these discussions are based on patterns from the past or the potential for bad actors.
Ph.D. candidate Shamika Klassen and I evaluated this teaching exercise in a research study and found that there are pedagogical benefits to encouraging computing students to imagine what might go wrong in the future – and then brainstorm about how we might avoid that future in the first place.
However, the purpose isn’t to prepare students for those far-flung futures; it is to teach speculation as a skill that can be applied immediately. This skill is especially important for helping students imagine harm to other people, since technological harms often disproportionately impact marginalized groups that are underrepresented in computing professions. The next steps for my research are to translate these ethical speculation strategies for real-world technology design teams.
Time to Hit Pause?
In March 2023, an open letter with thousands of signatures advocated for pausing training AI systems more powerful than GPT-4. Unchecked, AI development “might eventually outnumber, outsmart, obsolete and replace us,” or even cause a “loss of control of our civilization,” its writers warned.
As critiques of the letter point out, this focus on hypothetical risks ignores actual harms happening today. Nevertheless, I think there is little disagreement among AI ethicists that AI development needs to slow down – that developers throwing up their hands and citing “unintended consequences” is not going to cut it.
We are only a few months into the “AI race” picking up significant speed, and I think it’s already clear that ethical considerations are being left in the dust. But the debt will come due eventually – and history suggests that Big Tech executives and investors may not be the ones paying for it.
Watermarking ChatGPT and Other Generative AIs Could Help Protect Against Fraud and Misinformation
Shortly after rumors leaked of former President Donald Trump’s impending indictment, images purporting to show his arrest appeared online. These images looked like news photos, but they were fake. They were created by a generative artificial intelligence system.
Generative AI, in the form of image generators like DALL-E, Midjourney and Stable Diffusion, and text generators like Bard, ChatGPT, Chinchilla and LLaMA, has exploded in the public sphere. By combining clever machine-learning algorithms with billions of pieces of human-generated content, these systems can do anything from create an eerily realistic image from a caption, synthesize a speech in President Joe Biden’s voice, replace one person’s likeness with another in a video, or write a coherent 800-word op-ed from a title prompt.
This article was republished with permission from The Conversation, a news site dedicated to sharing ideas from academic experts. It represents the research-based findings and thoughts of, Hany Farid, Professor of Computer Science, University of California, Berkeley.
Even in these early days, generative AI is capable of creating highly realistic content. My colleague Sophie Nightingale and I found that the average person is unable to reliably distinguish an image of a real person from an AI-generated person. Although audio and video have not yet fully passed through the uncanny valley – images or models of people that are unsettling because they are close to but not quite realistic – they are likely to soon. When this happens, and it is all but guaranteed to, it will become increasingly easier to distort reality.
In this new world, it will be a snap to generate a video of a CEO saying her company’s profits are down 20%, which could lead to billions in market-share loss, or to generate a video of a world leader threatening military action, which could trigger a geopolitical crisis, or to insert the likeness of anyone into a sexually explicit video.
Advances in generative AI will soon mean that fake but visually convincing content will proliferate online, leading to an even messier information ecosystem. A secondary consequence is that detractors will be able to easily dismiss as fake actual video evidence of everything from police violence and human rights violations to a world leader burning top-secret documents.
As society stares down the barrel of what is almost certainly just the beginning of these advances in generative AI, there are reasonable and technologically feasible interventions that can be used to help mitigate these abuses. As a computer scientist who specializes in image forensics, I believe that a key method is watermarking.
Watermarks
There is a long history of marking documents and other items to prove their authenticity, indicate ownership and counter counterfeiting. Today, Getty Images, a massive image archive, adds a visible watermark to all digital images in their catalog. This allows customers to freely browse images while protecting Getty’s assets.
Imperceptible digital watermarks are also used for digital rights management. A watermark can be added to a digital image by, for example, tweaking every 10th image pixel so that its color (typically a number in the range 0 to 255) is even-valued. Because this pixel tweaking is so minor, the watermark is imperceptible. And, because this periodic pattern is unlikely to occur naturally, and can easily be verified, it can be used to verify an image’s provenance.
Even medium-resolution images contain millions of pixels, which means that additional information can be embedded into the watermark, including a unique identifier that encodes the generating software and a unique user ID. This same type of imperceptible watermark can be applied to audio and video.
The ideal watermark is one that is imperceptible and also resilient to simple manipulations like cropping, resizing, color adjustment and converting digital formats. Although the pixel color watermark example is not resilient because the color values can be changed, many watermarking strategies have been proposed that are robust – though not impervious – to attempts to remove them.
Watermarking and AI
These watermarks can be baked into the generative AI systems by watermarking all the training data, after which the generated content will contain the same watermark. This baked-in watermark is attractive because it means that generative AI tools can be open-sourced – as the image generator Stable Diffusion is – without concerns that a watermarking process could be removed from the image generator’s software. Stable Diffusion has a watermarking function, but because it’s open source, anyone can simply remove that part of the code.
OpenAI is experimenting with a system to watermark ChatGPT’s creations. Characters in a paragraph cannot, of course, be tweaked like a pixel value, so text watermarking takes on a different form.
Text-based generative AI is based on producing the next most-reasonable word in a sentence. For example, starting with the sentence fragment “an AI system can…,” ChatGPT will predict that the next word should be “learn,” “predict” or “understand.” Associated with each of these words is a probability corresponding to the likelihood of each word appearing next in the sentence. ChatGPT learned these probabilities from the large body of text it was trained on.
Generated text can be watermarked by secretly tagging a subset of words and then biasing the selection of a word to be a synonymous tagged word. For example, the tagged word “comprehend” can be used instead of “understand.” By periodically biasing word selection in this way, a body of text is watermarked based on a particular distribution of tagged words. This approach won’t work for short tweets but is generally effective with text of 800 or more words depending on the specific watermark details.
Generative AI systems can, and I believe should, watermark all their content, allowing for easier downstream identification and, if necessary, intervention. If the industry won’t do this voluntarily, lawmakers could pass regulation to enforce this rule. Unscrupulous people will, of course, not comply with these standards. But, if the major online gatekeepers – Apple and Google app stores, Amazon, Google, Microsoft cloud services and GitHub – enforce these rules by banning noncompliant software, the harm will be significantly reduced.
Signing Authentic Content
Tackling the problem from the other end, a similar approach could be adopted to authenticate original audiovisual recordings at the point of capture. A specialized camera app could cryptographically sign the recorded content as it’s recorded. There is no way to tamper with this signature without leaving evidence of the attempt. The signature is then stored on a centralized list of trusted signatures.
Although not applicable to text, audiovisual content can then be verified as human-generated. The Coalition for Content Provenance and Authentication (C2PA), a collaborative effort to create a standard for authenticating media, recently released an open specification to support this approach. With major institutions including Adobe, Microsoft, Intel, BBC and many others joining this effort, the C2PA is well positioned to produce effective and widely deployed authentication technology.
The combined signing and watermarking of human-generated and AI-generated content will not prevent all forms of abuse, but it will provide some measure of protection. Any safeguards will have to be continually adapted and refined as adversaries find novel ways to weaponize the latest technologies.
In the same way that society has been fighting a decadeslong battle against other cyber threats like spam, malware and phishing, we should prepare ourselves for an equally protracted battle to defend against various forms of abuse perpetrated using generative AI.
The Fear of Mass Unemployment Due to Artificial Intelligence and Robotics Is Unfounded
People are arguing over whether artificial intelligence (AI) and robotics will eliminate human employment. People seem to have an all-or-nothing belief that either the use of technology in the workplace will destroy human employment and purpose or it won’t affect it at all. The replacement of human jobs with robotics and AI is known as “technological unemployment.”
Although robotics can turn materials into economic goods in a fraction of the time it would take a human, in some cases using minimal human energy, some claim that AI and robotics will actually bring about increasing human employment. According to a 2020 Forbes projection, AI and robotics will be a strong creator of jobs and work for people across the globe in the near future. However, also in 2020, Daron Acemoglu and Pascual Restrepo published a study that projected negative job growth when AI and robotics replace human jobs, predicting significant job loss each time a robot replaces a human in the workplace. But two years later, an article in The Economist showed that many economists have backtracked on their projection of a high unemployment rate due to AI and robotics in the workplace. According to the 2022 Economist article, “Fears of a prolonged period of high unemployment did not come to pass. . . . The gloomy narrative, which says that an invasion of job-killing robots is just around the corner, has for decades had an extraordinary hold on the popular imagination.” So which scenario is correct?
Contrary to popular belief, no industrialized nation has ever completely replaced human energy with technology in the workplace. For instance, the steam shovel never put construction workers out of work; whether people want to work in construction is a different question. And bicycles did not become obsolete because of vehicle manufacturing: “Consumer spending on bicycles and accessories peaked at $8.3 billion in 2021,” according to an article from the World Economic Forum.
Do people generally think AI and robotics can run an economy without human involvement, energy, ingenuity, and cooperation? While AI and robotics have boosted economies, they cannot plan or run an economy or create technological unemployment worldwide. “Some countries are in better shape to join the AI competition than others,” according to the Carnegie Endowment for International Peace. Although an accurate statement, it misses the fact that productive economies adapt to technological changes better than nonproductive economies. Put another way, productive people are even more effective when they use technology. Firms using AI and robotics can lower production costs, lower prices, and stimulate demand; hence, employment grows if demand and therefore production increase. In the unlikely event that AI or robotic productive technology does not lower a firm’s prices and production costs, employment opportunities will decline in that industry, but employment will shift elsewhere, potentially expanding another industry’s capacity. This industry may then increase its use of AI and robotics, creating more employment opportunities there.
In the not-so-distant past, office administrators did not know how to use computers, but when the computer entered the workplace, it did not eliminate administrative employment as was initially predicted. Now here we are, walking around with minicomputers in our pants pockets. The introduction of the desktop computer did not eliminate human administrative workers—on the contrary, the computer has provided more employment since its introduction in the workplace. Employees and business owners, sometimes separated by time and space, use all sorts of technological devices, communicate with one another across vast networks, and can be increasingly productive.
I remember attending a retirement party held by a company where I worked decades ago. The retiring employee told us all a story about when the company brought in its first computer back in the late ’60s. The retiree recalled, “The boss said we were going to use computers instead of typewriters and paper to handle administrative tasks. The next day, her department went from a staff of thirty to a staff of five.” The day after the department installed computers, twenty-five people left the company to seek jobs elsewhere so they would not “have to learn and deal with them darn computers.”
People often become afraid of losing their jobs when firms introduce new technology, particularly technology that is able to replicate human tasks. However, mass unemployment due to technological innovation has never happened in any industrialized nation. The notion that AI will disemploy humans in the marketplace is unfounded. Mike Thomas noted in his article “Robots and AI Taking Over Jobs: What to Know about the Future of Jobs” that “artificial intelligence is poised to eliminate millions of current jobs—and create millions of new ones.” The social angst about the future of AI and robotics is reminiscent of the early nineteenth-century Luddites of England and their fear of replacement technology. Luddites, heavily employed in the textile industry, feared the weaving machine would take their jobs. They traveled throughout England breaking and vandalizing machines and new manufacturing technology because of their fear of technological unemployment. However, as the textile industry there became capitalized, employment in that industry actually grew. History tells us that technology drives the increase of work and jobs for humans, not the opposite.
We should look forward to unskilled and semiskilled workers’ upgrading from monotonous work because of AI and robotics. Of course, AI and robotics will have varying effects on different sectors; but as a whole, they are enablers and amplifiers of human work. As noted, the steam shovel did not disemploy construction workers. The taxi industry was not eliminated because of Uber’s technology; if anything, Uber’s new AI technology lowered the barriers of entry to the taxi industry. Musicians were not eliminated when music was digitized; instead, this innovation gave musicians larger platforms and audiences, allowing them to reach millions of people with the swipe of a screen. And dating apps running on AI have helped millions of people fall in love and live happily ever after.
About the Author
Raushan Gross is an Associate Professor of Business Management at Pfeiffer University. His works includeBasic Entrepreneurship, Management and Strategy, and the e-book The Inspiring Life and Beneficial Impact of Entrepreneurs.
Modern fabrication tools such as 3D printers can make structural materials in shapes that would have been difficult or impossible using conventional tools. Meanwhile, new generative design systems can take great advantage of this flexibility to create innovative designs for parts of a new building, car, or virtually any other device.
But such “black box” automated systems often fall short of producing designs that are fully optimized for their purpose, such as providing the greatest strength in proportion to weight or minimizing the amount of material needed to support a given load. Fully manual design, on the other hand, is time-consuming and labor-intensive.
Now, researchers (MIT) have found a way to achieve some of the best of both of these approaches. They used an automated design system but stopped the process periodically to allow human engineers to evaluate the work in progress and make tweaks or adjustments before letting the computer resume its design process. Introducing a few of these iterations produced results that performed better than those designed by the automated system alone, and the process was completed more quickly compared to the fully manual approach.
The results are reported this week in the journal Structural and Multidisciplinary Optimization, in a paper by MIT doctoral student Dat Ha and assistant professor of civil and environmental engineering Josephine Carstensen.
The basic approach can be applied to a broad range of scales and applications, Carstensen explains, for the design of everything from biomedical devices to nanoscale materials to structural support members of a skyscraper. Already, automated design systems have found many applications. “If we can make things in a better way, if we can make whatever we want, why not make it better?” she asks.
“It’s a way to take advantage of how we can make things in much more complex ways than we could in the past,” says Ha, adding that automated design systems have already begun to be widely used over the last decade in automotive and aerospace industries, where reducing weight while maintaining structural strength is a key need.
“You can take a lot of weight out of components, and in these two industries, everything is driven by weight,” he says. In some cases, such as internal components that aren’t visible, appearance is irrelevant, but for other structures, aesthetics may be important as well. The new system makes it possible to optimize designs for visual as well as mechanical properties, and in such decisions, the human touch is essential.
As a demonstration of their process in action, the researchers designed a number of structural load-bearing beams, such as might be used in a building or a bridge. In their iterations, they saw that the design has an area that could fail prematurely, so they selected that feature and required the program to address it. The computer system then revised the design accordingly, removing the highlighted strut and strengthening some other struts to compensate, and leading to an improved final design.
The process, which they call Human-Informed Topology Optimization, begins by setting out the needed specifications — for example, a beam needs to be this length, supported on two points at its ends, and must support this much of a load. “As we’re seeing the structure evolve on the computer screen in response to initial specification,” Carstensen says, “we interrupt the design and ask the user to judge it. The user can select, say, ‘I’m not a fan of this region, I’d like you to beef up or beef down this feature size requirement.’ And then the algorithm takes into account the user input.”
While the result is not as ideal as what might be produced by a fully rigorous yet significantly slower design algorithm that considers the underlying physics, she says it can be much better than a result generated by a rapid automated design system alone. “You don’t get something that’s quite as good, but that was not necessarily the goal. What we can show is that instead of using several hours to get something, we can use 10 minutes and get something much better than where we started off.”
The system can be used to optimize a design based on any desired properties, not just strength and weight. For example, it can be used to minimize fracture or buckling, or to reduce stresses in the material by softening corners.
Carstensen says, “We’re not looking to replace the seven-hour solution. If you have all the time and all the resources in the world, obviously you can run these and it’s going to give you the best solution.” But for many situations, such as designing replacement parts for equipment in a war zone or a disaster-relief area with limited computational power available, “then this kind of solution that catered directly to your needs would prevail.”
Similarly, for smaller companies manufacturing equipment in essentially “mom and pop” businesses, such a simplified system might be just the ticket. The new system they developed is not only simple and efficient to run on smaller computers, but it also requires far less training to produce useful results, Carstensen says. A basic two-dimensional version of the software, suitable for designing basic beams and structural parts, is freely available now online, she says, as the team continues to develop a full 3D version.
“The potential applications of Prof Carstensen’s research and tools are quite extraordinary,” says Christian Málaga-Chuquitaype, a professor of civil and environmental engineering at Imperial College London, who was not associated with this work. “With this work, her group is paving the way toward a truly synergistic human-machine design interaction.”
“By integrating engineering ‘intuition’ (or engineering ‘judgement’) into a rigorous yet computationally efficient topology optimization process, the human engineer is offered the possibility of guiding the creation of optimal structural configurations in a way that was not available to us before,” he adds. “Her findings have the potential to change the way engineers tackle ‘day-to-day’ design tasks.”
Image: Marine Corps Warfighting Laboratory MAGTAF Integrated Experiment (MCWL) 160709-M-OB268-165.jpg
War in Ukraine Accelerates Global Drive Toward Killer Robots
The U.S. military is intensifying its commitment to the development and use of autonomous weapons, as confirmed by an update to a Department of Defense directive. The update, released Jan. 25, 2023, is the first in a decade to focus on artificial intelligence autonomous weapons. It follows a related implementation plan released by NATO on Oct. 13, 2022, that is aimed at preserving the alliance’s “technological edge” in what are sometimes called “killer robots.”
Both announcements reflect a crucial lesson militaries around the world have learned from recent combat operations in Ukraine and Nagorno-Karabakh: Weaponized artificial intelligence is the future of warfare.
“We know that commanders are seeing a military value in loitering munitions in Ukraine,” Richard Moyes, director of Article 36, a humanitarian organization focused on reducing harm from weapons, told me in an interview. These weapons, which are a cross between a bomb and a drone, can hover for extended periods while waiting for a target. For now, such semi-autonomous missiles are generally being operated with significant human control over key decisions, he said.
Pressure of War
But as casualties mount in Ukraine, so does the pressure to achieve decisive battlefield advantages with fully autonomous weapons – robots that can choose, hunt down and attack their targets all on their own, without needing any human supervision.
This month, a key Russian manufacturer announced plans to develop a new combat version of its Marker reconnaissance robot, an uncrewed ground vehicle, to augment existing forces in Ukraine. Fully autonomous drones are already being used to defend Ukrainian energy facilities from other drones. Wahid Nawabi, CEO of the U.S. defense contractor that manufactures the semi-autonomous Switchblade drone, said the technology is already within reach to convert these weapons to become fully autonomous.
Mykhailo Fedorov, Ukraine’s digital transformation minister, has argued that fully autonomous weapons are the war’s “logical and inevitable next step” and recently said that soldiers might see them on the battlefield in the next six months.
Proponents of fully autonomous weapons systems argue that the technology will keep soldiers out of harm’s way by keeping them off the battlefield. They will also allow for military decisions to be made at superhuman speed, allowing for radically improved defensive capabilities.
Currently, semi-autonomous weapons, like loitering munitions that track and detonate themselves on targets, require a “human in the loop.” They can recommend actions but require their operators to initiate them.
This article was republished with permission from The Conversation, a news site dedicated to sharing ideas from academic experts. It represents the research-based findings and thoughts of, James Dawes, Professor, Macalester College.
By contrast, fully autonomous drones, like the so-called “drone hunters” now deployed in Ukraine, can track and disable incoming unmanned aerial vehicles day and night, with no need for operator intervention and faster than human-controlled weapons systems.
Calling for a Timeout
Critics like The Campaign to Stop Killer Robots have been advocating for more than a decade to ban research and development of autonomous weapons systems. They point to a future where autonomous weapons systems are designed specifically to target humans, not just vehicles, infrastructure and other weapons. They argue that wartime decisions over life and death must remain in human hands. Turning them over to an algorithm amounts to the ultimate form of digital dehumanization.
Together with Human Rights Watch, The Campaign to Stop Killer Robots argues that autonomous weapons systems lack the human judgment necessary to distinguish between civilians and legitimate military targets. They also lower the threshold to war by reducing the perceived risks, and they erode meaningful human control over what happens on the battlefield.
This composite image shows a ‘Switchblade’ loitering munition drone launching from a tube and extending its folded wings. U.S. Army AMRDEC Public Affairs
The organizations argue that the militaries investing most heavily in autonomous weapons systems, including the U.S., Russia, China, South Korea and the European Union, are launching the world into a costly and destabilizing new arms race. One consequence could be this dangerous new technology falling into the hands of terrorists and others outside of government control.
The updated Department of Defense directive tries to address some of the key concerns. It declares that the U.S. will use autonomous weapons systems with “appropriate levels of human judgment over the use of force.” Human Rights Watch issued a statement saying that the new directive fails to make clear what the phrase “appropriate level” means and doesn’t establish guidelines for who should determine it.
But as Gregory Allen, an expert from the national defense and international relations think tank Center for Strategic and International Studies, argues, this language establishes a lower threshold than the “meaningful human control” demanded by critics. The Defense Department’s wording, he points out, allows for the possibility that in certain cases, such as with surveillance aircraft, the level of human control considered appropriate “may be little to none.”
The updated directive also includes language promising ethical use of autonomous weapons systems, specifically by establishing a system of oversight for developing and employing the technology, and by insisting that the weapons will be used in accordance with existing international laws of war. But Article 36’s Moyes noted that international law currently does not provide an adequate framework for understanding, much less regulating, the concept of weapon autonomy.
The current legal framework does not make it clear, for instance, that commanders are responsible for understanding what will trigger the systems that they use, or that they must limit the area and time over which those systems will operate. “The danger is that there is not a bright line between where we are now and where we have accepted the unacceptable,” said Moyes.
Impossible Balance?
The Pentagon’s update demonstrates a simultaneous commitment to deploying autonomous weapons systems and to complying with international humanitarian law. How the U.S. will balance these commitments, and if such a balance is even possible, remains to be seen.
The International Committee of the Red Cross, the custodian of international humanitarian law, insists that the legal obligations of commanders and operators “cannot be transferred to a machine, algorithm or weapon system.” Right now, human beings are held responsible for protecting civilians and limiting combat damage by making sure the use of force is proportional to military objectives.
If and when artificially intelligent weapons are deployed on the battlefield, who should be held responsible when needless civilian deaths occur? There isn’t a clear answer to that very important question.
Will AI Learn to Become a Better Entrepreneur than You?
Contemporary businesses use artificial intelligence (AI) tools to assist with operations and compete in the marketplace. AI enables firms and entrepreneurs to make data-driven decisions and to quicken the data-gathering process. When creating strategy, buying, selling, and increasing marketplace discovery, firms need to ask: What is better, artificial or human intelligence?
A recent article from the Harvard Business Review, “Can AI Help You Sell?,” stated, “Better algorithms lead to better service and greater success.” The attributes of the successful entrepreneur, such as calculated risk taking, dealing with uncertainty, keen sense for market signals, and adjusting to marketplace changes might be a thing of the past. Can AI take the place of the human entrepreneur? Would sophisticated artificial intelligence be able to spot market prices better, adjust to expectations better, and steer production toward the needs of consumers better than a human?
In one of my classes this semester, students and I discussed the role of AI, deep machine learning, and natural language processing (NLP) in driving many of the decisions and operations a human would otherwise provide within the firm. Of course, half of the class felt that the integration of some level of AI into many firms’ operations and resource management is beneficial in creating a competitive advantage.
However, the other half felt using AI will inevitably disable humans’ function in the market economy, resulting in less and less individualism. In other words, the firm will be overrun by AI. We can see that even younger college students are on the fence about whether AI will eliminate humans’ function in the market economy. We concluded as a class that AI and machine learning have their promises and shortcomings.
After class, I started thinking about the digital world of entrepreneurship. E-commerce demands the use of AI to reach customers, sell goods, produce goods, and host exchange—in conjunction with a human entrepreneur, of course.
However, AI—machine learning or deep machine learning—could also be tasked with creating a business-based model, examining the data on customers’ needs, designing a web page, and creating ads. Could AI adjust to market action and react to market uncertainty like a human? The answer may be a resounding yes! So, could AI eliminate the human entrepreneur?
Algorithm-XLab explains deep machine learning as something that “allows computers to solve complex problems. These systems can even handle diverse masses of unstructured data set.” Algorithm-XLab compared deep learning with human learning favorably, stating, “While a human can easily lose concentration, and possibly make a mistake, a robot won’t.”
This statement by Algorithm-XLab challenges the idea that trial and error leads to greater market knowledge and better enables entrepreneurs to provide consumers with what they are willing to buy. The statement also portrays the marketplace as a process where people have perfect knowledge and an equilibrium point, and it implies that humans do not have specialized knowledge of time and place.
The use of AI and its tools of deep learning and language processing do have their benefits from a technical standpoint. AI can determine how to produce hula hoops better, but can it determine whether to produce them or devote energy elsewhere? If entrepreneurs discover market opportunities, they must weigh the advantages and disadvantages of their potential actions. Will AI have the same entrepreneurial foresight?
The acquisition of market knowledge can take humans years to acquire; AI is much faster at it than humans would be. For example, the Allen Institute for AI is “working on systems that can take science tests, which require a knowledge of unstated facts and common sense that humans develop over the course of their lives.” The ability to process unstated, scattered facts is precisely the kind of characteristic we attribute to entrepreneurs. Processes, changes, and choices characterize the operation of the market, and the entrepreneur is at the center of this market function.
There is no doubt that contemporary firms use deep learning for strategy, operations, logistics, sales, and record keeping for human resources (HR) decision-making, according to a Bain & Company article titled “HR’s New Digital Mandate.” While focused on HR, the digital mandate does lend itself to questioning the use of entrepreneurial thinking and strategy conducted within a firm. After AI has learned how to operate a firm using robotic process automation and NLP capacities to their maximum, might it outstrip the human natural entrepreneurial abilities?
AI is used in everyday life, such as self-checkout at the grocery store, online shopping, social media interaction, dating apps, and virtual doctor appointments. Product delivery, financing, and development services increasingly involve an AI-as-a-service component. AI as a service minimizes the costs of gathering and processing customer insights, something usually associated with a team of human minds projecting key performance indicators aligned with an organizational strategy.
The human entrepreneur has a competitive advantage insofar as handling ambiguous customer feedback and in effect creating an entrepreneurial response and delivering satisfaction. We seek to determine whether AI has replaced human energy in some areas of life. Can AI understand human uneasiness or dissatisfaction, or the subjectivity of value felt by the consumer? AI can produce hula hoops, but can it articulate plans and gather the resources needed to produce them in the first place?.
In what, if any, entrepreneurial functions can AI outperform the human entrepreneur? The human entrepreneur is willing to take risks, adjust to the needs of consumers, pick up price signals, and understand customer choices. Could the human entrepreneur soon become an extinct class? If so, would machine learning and natural processing AI understand the differences between free and highly regulated markets? If so, which would it prefer, or which would it create?
Getting to Know ChatGPT: A Shallow Dip into Its Current Functionality and Future Potential
ChatGPT and the underlying AI technology are, as near as anyone can tell, the next-level toolkit for research, communication, idea generation, and a million other uses. If you haven’t introduced yourself to it yet, leave plenty of time – getting started is easy, but getting yourself to stop may not be. Those of us that were around pre-internet may liken the first-time experience to the first time we gained access to the world wide web. The Sudden, much easier access to a world of information, puts one in a place where you don’t know what to try first.
Over the past couple of months, the now-familiar name, ChatGPT has made headlines. It quickly captivated the worlds imagination as an AI product that is likely to disrupt or destroy some industries while enhancing others. Obviously, this is of particular interest to investors. With this in mind, I sat down for an interview with ChatGPT; below are answers to questions that many investors are asking.
Channelchek (PH) – Am I able to interview Chatgpt?
ChatGPT – Hello! As an AI language model, I’m happy to answer any questions you may have. However, it’s important to keep in mind that I don’t have personal experiences or opinions like a human, and I can only provide information based on my training data. So feel free to ask me anything!
Channelchek (PH) – What do most users have ChatGPT to do for them?
ChatGPT – As an AI language model, ChatGPT can be used for a wide range of tasks, including:
Language translation: ChatGPT can be used to translate text from one language to another.
Content creation: ChatGPT can generate text for various types of content, such as articles, blog posts, and product descriptions.
Chatbot development: ChatGPT can be used to develop chatbots that can interact with users and provide information.
Sentiment analysis: ChatGPT can be used to analyze the sentiment of a piece of text, such as a social media post or a product review.
Question-answering: ChatGPT can be used to answer questions on a wide range of topics.
Text summarization: ChatGPT can be used to summarize long pieces of text into shorter, more manageable summaries.
Language modeling: ChatGPT can be used to train new models for specific domains, such as medical or legal language.
These are just a few examples of what ChatGPT can be used for. Its versatility and flexibility make it a powerful tool for many different applications.
Channelchek (PH) – From where do you pull your answers ChatGPT?
ChatGPT – As an AI language model, I don’t have pre-programmed answers. Instead, I generate responses to questions by analyzing patterns in large amounts of text data that I was trained on. Specifically, I was trained on a dataset of billions of words from various sources, including books, articles, websites, and other textual sources. During my training, I was exposed to a wide range of topics and writing styles, which helps me generate responses to many different types of questions.
When you ask me a question, I use natural language processing (NLP) techniques to analyze the question and generate a response based on patterns in the text data that I was trained on. I then use statistical models to determine the most likely response based on the context of the question and the patterns in the training data.
It’s important to note that my responses are only as accurate and reliable as the patterns that I learned during my training. While I strive to provide accurate and helpful information, I may not always get it right, and my responses may not reflect the views or opinions of OpenAI.
Channelchek (PH) – Are you at risk of having the response you generate slanted or biased based on users feedback adjusting your training ChatGPT?
ChatGPT – As an AI language model, I am designed to learn from the data that I am trained on, including the feedback that users provide to adjust my training. However, it’s important to be aware that the feedback that users provide can sometimes introduce biases into my training.
If the feedback is consistently biased in a particular direction, this could affect the accuracy and fairness of my responses. This is why it’s important to carefully monitor and evaluate any feedback that is used to adjust my training, and to ensure that it is representative of a wide range of perspectives.
To address this issue, OpenAI has implemented a number of safeguards to prevent bias and ensure that my training data is as accurate and diverse as possible. For example, the training data is carefully curated to include a wide range of sources and perspectives, and the training process is carefully monitored to ensure that biases are not introduced.
Additionally, OpenAI has implemented a number of techniques to help identify and mitigate any biases that may be present in the training data or feedback. For example, I am periodically evaluated to ensure that my responses are accurate and unbiased, and any issues that are identified are addressed through additional training or other adjustments to the model.
Channelchek (PH) – As an editor I write for Channelchek about stocks, the financial markets, the economy and business climate. Are you a good resource for current events related to these topics ChatGPT?
ChatGPT – As an AI language model, I can certainly provide you with information on current events related to stocks, financial markets, the economy, and the business climate. I have been trained on a vast amount of text data, including news articles and other sources related to these topics, so I can provide you with up-to-date information and insights on current events.
When asking me questions related to these topics, it’s important to provide me with as much context and specificity as possible so that I can provide you with the most accurate and relevant information. For example, if you are looking for information on a particular company or sector, you could provide me with the name of the company or sector, as well as any other relevant details or questions you may have.
However, it’s important to note that my responses are generated based on patterns in the text data that I was trained on, and may not reflect the views or opinions of OpenAI. Additionally, while I can provide you with information on current events and trends, I cannot provide investment advice or make predictions about future market performance. It’s always important to carefully evaluate information and seek the advice of a qualified financial professional before making investment decisions.
Channelchek (PH) – Do users ask you to forecast the stock market direction?
ChatGPT – Yes, users sometimes ask me to forecast the direction of the stock market. However, as an AI language model, I cannot make accurate predictions about future market performance. While I can provide information on current market trends and historical data, predicting the future direction of the stock market is a highly complex task that involves a range of economic, political, and social factors.
It’s important to note that investing in the stock market involves a certain degree of risk, and investors should always carefully evaluate market conditions and seek the advice of a qualified financial professional before making investment decisions. While I can provide general information and insights related to stocks and financial markets, I cannot provide investment advice or predict the future performance of individual stocks or the overall market.
Channelchek (PH) – Are you familiar with Channelchek?
ChatGPT – While I am not specifically programmed to be familiar with individual websites, I may have come across content from Channelchek during my training.
That being said, I can still provide you with general information on what Channelchek is. From my understanding, Channelchek is a financial information platform that provides independent research, analysis, and market commentary on publicly traded companies. It offers a range of tools and resources for investors and financial professionals, including market data, stock quotes, and research reports.
Channelchek’s focus is on providing unbiased and independent information to help investors make informed investment decisions.
Channelchek (PH) – Does your AI technology pose a risk to traditional internet search engines?
ChatGPT – My purpose is not to compete with traditional search engines like Google or Bing, but rather to complement them by providing an additional source of information and assistance to users. While I am capable of providing answers to a wide range of questions and generating responses to open-ended queries, I am not designed to replace traditional search engines or web browsing.
Search engines like Google and Bing are still the primary means by which users navigate the internet and find information, and they use a range of sophisticated algorithms and machine learning techniques to index and rank content on the web. While I am capable of processing natural language queries and generating responses, my training data is based on pre-existing content, which means that my responses are generated based on patterns in the text data that I was trained on, rather than direct access to the vast amounts of data on the internet.
Early Boolean Phrase Search Tool
Overall, AI language models like me are part of a larger ecosystem of tools and technologies that are designed to help users access and navigate the vast amount of information available online. While there may be some overlap between the capabilities of traditional search engines and AI language models, both serve different purposes and can work together to provide users with the most comprehensive and accurate information possible.
Channelchek (PH) – What industries are you likely to disrupt and which are you likely to augment or help build?
ChatGPT – As an AI language model, my capabilities are quite broad, and I have the potential to impact a wide range of industries and areas of society. Here are a few ways in which I could potentially disrupt or augment various industries:
Industries that could be disrupted:
Customer service: AI language models like me are already being used by many companies to automate and improve customer service interactions, and this trend is likely to continue. As AI technology improves, it could potentially replace many human customer service jobs.
Content creation: AI language models have the potential to automate certain types of content creation, such as news articles, product descriptions, and even social media posts. This could have a significant impact on the journalism and writing industries.
Education: AI language models could potentially disrupt the traditional education model by providing personalized learning experiences and automating certain types of teaching and grading.
Industries that could be augmented:
Healthcare: AI language models could help augment healthcare by providing more accurate and personalized diagnoses, and by automating certain types of administrative tasks.
Finance: AI language models could help augment finance by providing more accurate and data-driven investment advice, and by automating certain types of financial analysis.
Research: AI language models could help augment research by processing and analyzing vast amounts of data, and by identifying patterns and insights that might be difficult for humans to spot on their own.
Overall, the impact of AI language models like me on various industries will depend on a wide range of factors, including the development of the technology, the regulatory environment, and societal attitudes toward automation and AI. While there may be some industries that are more susceptible to disruption or augmentation than others, it’s important to approach these developments with a nuanced understanding of the potential benefits and risks.
Channelchek (PH) – Are users using ChatGPT to create social media bots to respond without human intervention likely to flood the internet?
ChatGPT – While it is technically possible for users to use AI language models like ChatGPT to create social media bots that can respond to messages without human intervention, I cannot speculate on whether this is likely to flood the internet.
The use of AI language models like ChatGPT could potentially make it easier and more accessible for users to create more sophisticated chatbots that can mimic human conversation more convincingly.
It’s also important to consider the potential impact of widespread use of social media bots on the quality and authenticity of online interactions. While chatbots can be useful in certain contexts, they can also be used to spread misinformation and propaganda or to manipulate public opinion. As with any technology, it’s important to approach the use of AI language models and chatbots in a responsible and ethical way, and to consider the potential risks and benefits of their use.
Channelchek (PH) – What do you call one that uses ChatGPT?
ChatGPT – There is no specific term for a person who uses ChatGPT or other AI language models, as these tools are designed to be accessible and usable by anyone with an internet connection.
However, a person who uses ChatGPT to create chatbots or other automated tools could be referred to as an AI developer or AI engineer. Similarly, a person who uses ChatGPT to conduct research or analysis in a specific field could be referred to as an AI researcher or analyst.
Channelchek (PH) – How much do you cost?
As an AI language model, I do not have a specific cost as I am not a commercial product. My purpose is to provide information and assistance to users like you, and I am freely accessible through various platforms that integrate my technology, including chatbots, voice assistants, and search engines.
Channelchek (PH) – Should I throw out the encyclopedias on my book shelf and rely instead on ChatGPT?
ChatGPT – Ultimately, whether or not to keep your encyclopedias depends on your personal preferences and how you prefer to access information. While AI language models like ChatGPT are convenient and accessible, they may not always provide the level of detail or accuracy that you require for a specific question or topic. So, it’s always a good idea to consult multiple sources of information to ensure that you have a well-rounded understanding of a given topic.
Channelchek (PH) – How does one get started using ChatGPT for research?
ChatGPT – Getting started with using ChatGPT for research can involve several steps. Here are a few basic steps you can follow:
Identify your research question or topic: Start by identifying the research question or topic you want to investigate. This will help you to focus your search and make the best use of ChatGPT.
Choose a ChatGPT platform: There are several platforms that integrate ChatGPT, including chatbots, voice assistants, and search engines. Choose a platform that best fits your needs and preferences.
Familiarize yourself with the platform: Once you have chosen a platform, take some time to explore and familiarize yourself with its features and capabilities. Many platforms offer tutorials and guides to help you get started.
Start asking questions: Once you are comfortable with the platform, start asking questions related to your research topic. Try to ask open-ended questions that will allow ChatGPT to provide more detailed and relevant answers.
Evaluate the results: As you receive answers from ChatGPT, evaluate the accuracy and relevance of the information. Keep in mind that ChatGPT is not perfect and may not always provide the most accurate or comprehensive information. Be sure to double-check any information you receive with other sources to ensure its accuracy.
Refine your search: If you are not finding the information you need, try refining your search by using more specific keywords or phrases.
Overall, using ChatGPT for research can be a valuable tool for gathering information and conducting preliminary investigations. However, it’s important to keep in mind that it is just one tool in the research process, and should be used in conjunction with other sources of information and research methods.
Wrap Up
It’s easy to comprehend how this technology, which will likely see stronger competition in the coming year, will quickly become something that is used every day to help streamline how we do our jobs, and find information in our personal lives. Unlike an internet search engine, queries produce individual results tailored to the individual question. The same question will recieve different phraseology if asked a minute later. Whereas Google or DuckDuckGo list websites that may provide the answer, ChatGPT responds using its own answer using artificial intelligence.
Getting started is as easy as going to OpenAI.com and navigating to Chat.OpenAI.com and providing an email and verification phone number. Click on my name below and write me, I’d love to hear what you are using it for.
Recent Investment Trends Include Small-Cap Artificial Intelligence Stocks
C3 AI, sometimes written C3.ai, is an artificial intelligence platform that provides services for companies to build large-scale AI applications. Its stock had the fifth highest traded shares among Fidelity’s retail investors on Monday (February 6). This included a record-breaking $31.4 million worth of shares traded among the broker’s individual self-directed traders. According to Reuters, “Retail investors are piling up on small-cap firms that employ artificial intelligence amid intensifying competition between tech titans.” The article points to Google and Microsoft as examples of companies that expect AI to be the next meaningful driver of growth.
Investors, for their part, are looking to get ahead of any acquisition spree that deep-pocketed companies may embark on, which could include buying the advanced technology by acquiring small-cap tech firms.
Focus Heightened by ChatGPT
The spotlight ChatGPT finds itself in, three months after its launch, is indicicative of the interest in this technology amongst investors and users. With applications as numerous than one can think up, the technology could outdate many services provided by tech companies like Alphabet (GOOGL), or Microsoft (MSFT) – big tech has catching up to do. This seems to have created a race by cash rich companies to not be disrupted and left behind.
Investor’s recent focus on small companies in this space prefer those that are concentrated in AI technology. One main reason is that small-cap or microcap firms in this space are likely to have AI as a more concentrated part of their business. The bet being that whether the small company continues to grow independently, or is acquired by a larger firm looking to instantly be par with current technology, doesn’t much matter, it is a win for the investor if either occurs.
And it is a win, C3 AI stock rallied 46% last week, and climbed another 6.5% on Monday. It is now up 146% year to date.
Other Companies Involved
SoundHound AI, provides a voice AI platform services, and Thailand-based security firm Guardforce AI have more than doubled so far this year, while analytics firm BigBear.AI has increased ninefold.
US-listed shares of Baidu Inc climbed after the Chinese search engine indicated it would complete an internal test of a ChatGPT-style project called “Ernie Bot” next month.
Shares of Microsoft, which supports ChatGPT parent OpenAI, had been ratcheting up over the past month. The company is expected to make an announcement on their AI gained 1.5% in premarket trading ahead of the AI plans this week.
Google-owner Alphabet Inc said this week it would launch Bard, a chatbot service for developers, alongside its search engine.
Take Away
Change in technology that leads to improvements in daily lives has always been a focus of investors betting on which companies will outlast the others with “the next big thing.” These companies start out as small growth companies as Apple (AAPL) did in 1976. Then, a number of paths lay ahead. They either grow on their own like the Jobs/Wozniak computer maker did, get acquired for an early payday for investors and other stakeholders, or they can be outcompeted leaving investors with a non-performing asset.
Channelchek is a platform that specializes in bringing data and research on small-cap companies, including many varieties of new technology, to the investors that insist on being informed before they place a trade. Discover more on the industries of tomorrow by signing up for notifications in your inbox from Channelchek by registering here.
Deepfake Audio Has a Tell – Researchers Use Fluid Dynamics to Spot Artificial Imposter Voices
Imagine the following scenario. A phone rings. An office worker answers it and hears his boss, in a panic, tell him that she forgot to transfer money to the new contractor before she left for the day and needs him to do it. She gives him the wire transfer information, and with the money transferred, the crisis has been averted.
The worker sits back in his chair, takes a deep breath, and watches as his boss walks in the door. The voice on the other end of the call was not his boss. In fact, it wasn’t even a human. The voice he heard was that of an audio deepfake, a machine-generated audio sample designed to sound exactly like his boss.
Attacks like this using recorded audio have already occurred, and conversational audio deepfakes might not be far off.
Deepfakes, both audio and video, have been possible only with the development of sophisticated machine learning technologies in recent years. Deepfakes have brought with them a new level of uncertainty around digital media. To detect deepfakes, many researchers have turned to analyzing visual artifacts – minute glitches and inconsistencies – found in video deepfakes.
Audio deepfakes potentially pose an even greater threat, because people often communicate verbally without video – for example, via phone calls, radio and voice recordings. These voice-only communications greatly expand the possibilities for attackers to use deepfakes.
To detect audio deepfakes, we and our research colleagues at the University of Florida have developed a technique that measures the acoustic and fluid dynamic differences between voice samples created organically by human speakers and those generated synthetically by computers.
Organic vs. Synthetic voices
Humans vocalize by forcing air over the various structures of the vocal tract, including vocal folds, tongue and lips. By rearranging these structures, you alter the acoustical properties of your vocal tract, allowing you to create over 200 distinct sounds, or phonemes. However, human anatomy fundamentally limits the acoustic behavior of these different phonemes, resulting in a relatively small range of correct sounds for each.
In contrast, audio deepfakes are created by first allowing a computer to listen to audio recordings of a targeted victim speaker. Depending on the exact techniques used, the computer might need to listen to as little as 10 to 20 seconds of audio. This audio is used to extract key information about the unique aspects of the victim’s voice.
The attacker selects a phrase for the deepfake to speak and then, using a modified text-to-speech algorithm, generates an audio sample that sounds like the victim saying the selected phrase. This process of creating a single deepfaked audio sample can be accomplished in a matter of seconds, potentially allowing attackers enough flexibility to use the deepfake voice in a conversation.
This article was republished with permission from The Conversation, a news site dedicated to sharing ideas from academic experts. It represents the research-based findings and thoughts of Logan Blue, PhD student in Computer & Information Science & Engineering, University of Florida and Patrick Traynor, Professor of Computer and Information Science and Engineering, University of Florida.
Detecting Audio Deepfakes
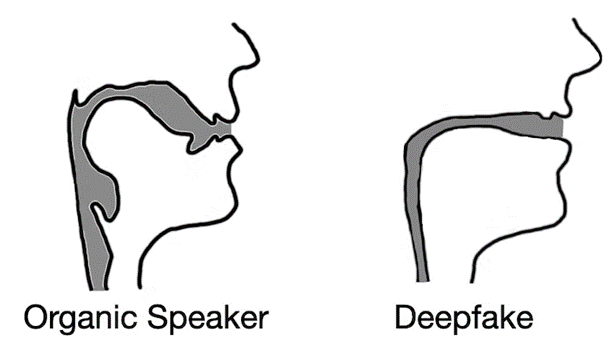
The first step in differentiating speech produced by humans from speech generated by deepfakes is understanding how to acoustically model the vocal tract. Luckily scientists have techniques to estimate what someone – or some being such as a dinosaur – would sound like based on anatomical measurements of its vocal tract.
We did the reverse. By inverting many of these same techniques, we were able to extract an approximation of a speaker’s vocal tract during a segment of speech. This allowed us to effectively peer into the anatomy of the speaker who created the audio sample.
Deepfaked audio often results in vocal tract reconstructions that resemble drinking straws rather than biological vocal tracts. Logan Blue (The Conversation)
From here, we hypothesized that deepfake audio samples would fail to be constrained by the same anatomical limitations humans have. In other words, the analysis of deepfaked audio samples simulated vocal tract shapes that do not exist in people.
Our testing results not only confirmed our hypothesis but revealed something interesting. When extracting vocal tract estimations from deepfake audio, we found that the estimations were often comically incorrect. For instance, it was common for deepfake audio to result in vocal tracts with the same relative diameter and consistency as a drinking straw, in contrast to human vocal tracts, which are much wider and more variable in shape.
This realization demonstrates that deepfake audio, even when convincing to human listeners, is far from indistinguishable from human-generated speech. By estimating the anatomy responsible for creating the observed speech, it’s possible to identify the whether the audio was generated by a person or a computer.
Why this matters
Today’s world is defined by the digital exchange of media and information. Everything from news to entertainment to conversations with loved ones typically happens via digital exchanges. Even in their infancy, deepfake video and audio undermine the confidence people have in these exchanges, effectively limiting their usefulness.
If the digital world is to remain a critical resource for information in people’s lives, effective and secure techniques for determining the source of an audio sample are crucial.














{kind=link}
{kind=link}